文章出處
文章列表
我們先了解下InnoDB引擎表的一些關鍵特征:
- InnoDB引擎表是基于B+樹的索引組織表(IOT);
- 每個表都需要有一個聚集索引(clustered index);
- 所有的行記錄都存儲在B+樹的葉子節點(leaf pages of the tree);
- 基于聚集索引的增、刪、改、查的效率相對是最高的;
- 如果我們定義了主鍵(PRIMARY KEY),那么InnoDB會選擇其作為聚集索引;
- 如果沒有顯式定義主鍵,則InnoDB會選擇第一個不包含有NULL值的唯一索引作為主鍵索引;
- 如果也沒有這樣的唯一索引,則InnoDB會選擇內置6字節長的ROWID作為隱含的聚集索引(ROWID隨著行記錄的寫入而主鍵遞增,這個ROWID不像ORACLE的ROWID那樣可引用,是隱含的)。
綜上總結,如果InnoDB表的數據寫入順序能和B+樹索引的葉子節點順序一致的話,這時候存取效率是最高的,也就是下面這幾種情況的存取效率最高:
- 使用自增列(INT/BIGINT類型)做主鍵,這時候寫入順序是自增的,和B+數葉子節點分裂順序一致;
- 該表不指定自增列做主鍵,同時也沒有可以被選為主鍵的唯一索引(上面的條件),這時候InnoDB會選擇內置的ROWID作為主鍵,寫入順序和ROWID增長順序一致;
- 除此以外,如果一個InnoDB表又沒有顯示主鍵,又有可以被選擇為主鍵的唯一索引,但該唯一索引可能不是遞增關系時(例如字符串、UUID、多字段聯合唯一索引的情況),該表的存取效率就會比較差。
實際情況是如何呢?經過簡單TPCC基準測試,修改為使用自增列作為主鍵與原始表結構分別進行TPCC測試,前者的TpmC結果比后者高9%倍,足見使用自增列做InnoDB表主鍵的明顯好處,其他更多不同場景下使用自增列的性能提升可以自行對比測試下。
附圖:
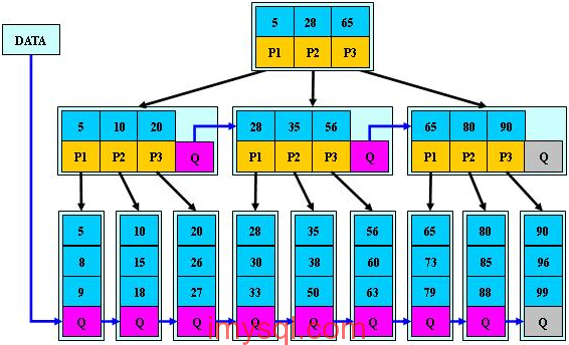
1、B+樹典型結構
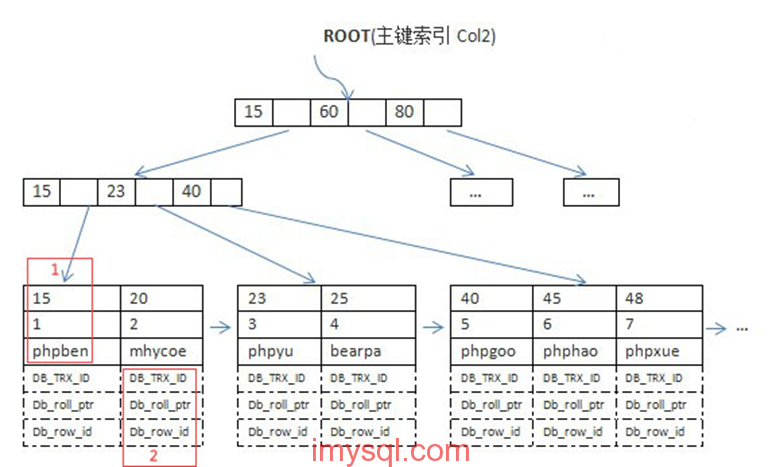
2、InnoDB主鍵邏輯結構
延伸閱讀:
2、B+Tree index structures in InnoDB
文章列表
全站熱搜


 留言列表
留言列表
