.NET內存管理、垃圾回收
1. Stack和Heap
每個線程對應一個stack,線程創建的時候CLR為其創建這個stack,stack主要作用是記錄函數的執行情況。值類型變量(函數的參數、局部變量 等非成員變量)都分配在stack中,引用類型的對象分配在heap中,在stack中保存heap對象的引用指針。GC只負責heap對象的釋 放,heap內存空間管理
Heap內存分配

除去pinned object等影響,heap中的內存分配很簡單,一個指針記錄heap中分配的起始地址,根據對象大小連續的分配內存
Stack結構
每個函數調用時,邏輯上在thread stack中會產生一個幀(stack frame),函數返回時對應的stack frame被釋放掉
用個簡單的函數查看執行時CLR對棧的處理情況:
{
int r = Sum(2, 3, 4, 5, 6);
}
private static int Sum(int a, int b, int c, int d, int e)
{
return a + b + c + d + e;
}
JIT編譯后主要匯編代碼如下(其他的情況下匯編代碼可能有所差別,但用這個簡單函數大致看下棧的管理已經足夠):
push 4 ;第3個參數到最后一個參數壓棧
push 5
push 6
mov edx,3 ;第1、第2個參數分別放入ecx、edx寄存器
mov ecx,2
call dword ptr ds:[00AD96B8h] ;調用函數Sum,執行call的時候返回地址(即下面這條mov語句的地址)自動壓棧 了
mov dword ptr [ebp-0Ch],eax ;將函數返回值設置到局部變量r中(函數調用結束返回值在eax寄存器中)
;====函數Sum====
push ebp ;保存原始ebp寄存器
mov ebp,esp ;將當前棧指針保存在ebp中,后面使用ebp對參數和局部變量尋址
sub esp,8 ;分配兩個局部變量
mov dword ptr [ebp-4],ecx ;第1個參數放入局部變量
mov dword ptr [ebp-8],edx ;第2個參數放入局部變量
...... ;CLR的檢查代碼
mov eax,dword ptr [ebp-4] ;a + b + c + d + e
add eax,dword ptr [ebp-8] ;第1個參數+第2個參數(2+3)
add eax,dword ptr [ebp+10h] ;+第3個參數(4)
add eax,dword ptr [ebp+0Ch] ;+第4個參數(5)
add eax,dword ptr [ebp+8] ;+第5個參數(6)
mov esp,ebp ;恢復棧指針(局部變量被釋放了)
pop ebp ;恢復原始的ebp寄存器值
ret 0Ch ;函數返回. 1: 返回地址自動出 棧; 2: esp減去0Ch(12個字節),即從棧中清除調用參 數; 3: 返回值在eax寄存器中
執行時刻的stack狀態如下(棧基地址為高端地址,棧頂為低端地址):

Stack狀態變化過程:
a). 調用者將第3、第4、第5個參數壓棧,第1、第2個參數分別放入ecx、edx寄存器
b). call指令調用函數Sum,并自動將函數返回地址壓棧,代碼跳轉到函數Sum開始執行
c). 函數Sum先將寄存器ebp壓棧保存,并將esp放入ebp,用于后面對參數和局部變量尋址
d). 定義局部變量以及省略掉的是額外代碼,跟Sum函數業務無關
e). 執行加法操作,結果保存在eax寄存器中
f). 恢復esp寄存器,這樣函數Sum中所有的局部變量以及其他壓棧操作全部釋放出來
g). 原始ebp的值出棧,恢復ebp,這樣棧完全恢復到進入Sum函數調用時的狀態
h). ret指令執行函數返回,返回值在eax寄存器中,返回地址為call指令壓棧的地址,返回地址自動出棧。0Ch指示處理器在函數返回時釋放棧中12個字 節,即由被調用者清除壓棧的參數。函數返回之后,本次Sum調用的棧分配全部釋放
這種調用約定類似__fastcall
結合引用類型變量、值類型的ref參數,下面代碼簡化的stack狀態如下:
代碼:
{
int j = 9;
MyClass1 c = new MyClass1();
c.x = 8;
int result = Sum(i, 5, ref j, c);
}
public static int Sum(int a, int b, ref int c, MyClass1 obj)
{
int r = a + b + c + obj.x;
return r;
}
public class MyClass1
{
public int x;
}
Stack狀態:
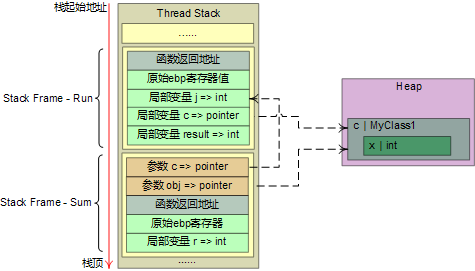
任何時候引用類型都分配在heap中,在stack中只是保存對象的引用地址。Run函數執行完畢之后,heap中的MyClass1對象c成為可回收的垃圾對象,在GC時進行回收
2. Mark-Compact 標記壓縮算法
簡單把.NET的GC算法看作Mark-Compact算法
階段1: Mark-Sweep 標記清除階段
先假設heap中所有對象都可以回收,然后找出不能回收的對象,給這些對象打上標記,最后heap中沒有打標記的對象都是可以被回收的
階段2: Compact 壓縮階段
對象回收之后heap內存空間變得不連續,在heap中移動這些對象,使他們重新從heap基地址開始連續排列,類似于磁盤空間的碎片整理

Heap內存經過回收、壓縮之后,可以繼續采用前面的heap內存分配方法,即僅用一個指針記錄heap分配的起始地址就可以。
主要處理步驟:將線程掛起=>確定roots=>創建reachable objects graph=>對象回收=>heap壓縮=>指針修復
可以這樣理解roots:heap中對象的引用關系錯綜復雜(交叉引用、循環引用),形成復雜的graph,roots是CLR在heap之外可以找到的 各種入口點。GC搜索roots的地方包括全局對象、靜態變量、局部對象、函數調用參數、當前CPU寄存器中的對象指針(還有finalization queue)等。主要可以歸為2種類型:已經初始化了的靜態變量、線程仍在使用的對象(stack+CPU register)
Reachable objects:指根據對象引用關系,從roots出發可以到達的對象。例如當前執行函數的局部變量對象A是一個root object,他的成員變量引用了對象B,則B是一個reachable object。從roots出發可以創建reachable objects graph,剩余對象即為unreachable,可以被回收

指針修復是因為compact過程移動了heap對象,對象地址發生變化,需要修復所有引用指針,包括stack、CPU register中的指針以及heap中其他對象的引用指針
Debug和release執行模式之間稍有區別,release模式下后續代碼沒有引用的對象是unreachable的,而debug模式下需要等到 當前函數執行完畢,這些對象才會成為unreachable,目的是為了調試時跟蹤局部對象的內容
傳給了COM+的托管對象也會成為root,并且具有一個引用計數器以兼容COM+的內存管理機制,引用計數器為0時這些對象才可能成為被回收對象
Pinned objects指分配之后不能移動位置的對象,例如傳遞給非托管代碼的對象(或者使用了fixed關鍵字),GC在指針修復時無法修改非托管代碼中的引用 指針,因此將這些對象移動將發生異常。pinned objects會導致heap出現碎片,但大部分情況來說傳給非托管代碼的對象應當在GC時能夠被回收掉
3. Generational 分代算法
程序可能使用幾百M、幾G的內存,對這樣的內存區域進行GC操作成本很高,分代算法具備一定統計學基礎,對GC的性能改善效果比較明顯
將對象按照生命周期分成新的、老的,根據統計分布規律所反映的結果,可以對新、老區域采用不同的回收策略和算法,加強對新區域的回收處理力度,爭取在較短 時間間隔、較小的內存區域內,以較低成本將執行路徑上大量新近拋棄不再使用的局部對象及時回收掉
分代算法的假設前提條件:
a). 大量新創建的對象生命周期都比較短,而較老的對象生命周期會更長
b). 對部分內存進行回收比基于全部內存的回收操作要快
c). 新創建的對象之間關聯程度通常較強。heap分配的對象是連續的,關聯度較強有利于提高CPU cache的命中率
.NET將heap分成3個代齡區域: Gen 0、Gen 1、Gen 2
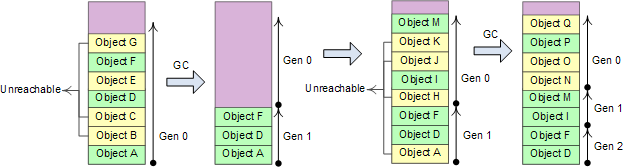
Heap分為3個代齡區域,相應的GC有3種方式: # Gen 0 collections, # Gen 1 collections, # Gen 2 collections。如果Gen 0 heap內存達到閥值,則觸發0代GC,0代GC后Gen 0中幸存的對象進入Gen 1。如果Gen 1的內存達到閥值,則進行1代GC,1代GC將Gen 0 heap和Gen 1 heap一起進行回收,幸存的對象進入Gen 2。2代GC將Gen 0 heap、Gen 1 heap和Gen 2 heap一起回收
Gen 0和Gen 1比較小,這兩個代齡加起來總是保持在16M左右;Gen 2的大小由應用程序確定,可能達到幾G,因此0代和1代GC的成本非常低,2代GC稱為full GC,通常成本很高。粗略的計算0代和1代GC應當能在幾毫秒到幾十毫秒之間完成,Gen 2 heap比較大時full GC可能需要花費幾秒時間。大致上來講.NET應用運行期間2代、1代和0代GC的頻率應當大致為1:10:100
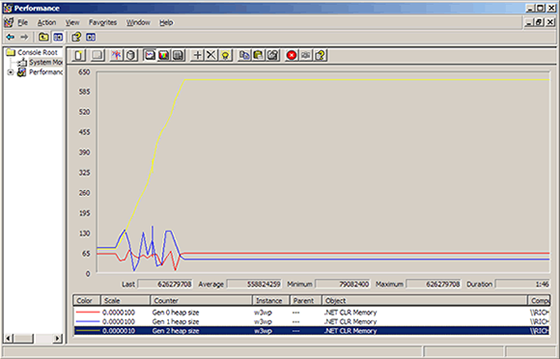
圖為一個ASP.NET程序運行的Performance Moniter,Gen 0 heap size(紅色)平均6M,Gen 1(藍色)平均5M,Gen 2(黃色)達到620M,Gen 0+Gen 1平均13.2M,最大19.8M
直觀上來看,程序的運行由一系列函數調用組成,函數運行期間會創建很多局部對象,函數結束之后也就產生大量待回收的對象。采用分代算法加強較新代齡的垃圾 回收力度,通常能夠極大的提高垃圾回收效率,否則就是極特殊的程序,或者是不合理的對象關聯設計。例如ASP.NET程序,應當確保絕大部分用于HTTP 請求處理的對象在0代和1代垃圾回收中被釋放掉
為heap記錄幾個指針可以確定代齡區域范圍,創建reachable objects graph時根據對象的地址可以確定對象位于哪個代齡區域,0代GC在創建graph時如果遇到1代、2代heap對象,可以直接越過不用繼續遍歷下去, 較老代齡的對象如果引用了較新代齡的對象,可以通過Win32 API GetWriteWatch訂閱內存更新通知,記錄在"card table"中,輔助較低代齡的GC正確構造graph
4. LOH
.NET 1.1和2.0中,85000字節以下的對象稱為小對象,分配在Gen 0 heap中,85000字節以上的對象稱為大對象,分配在Large Object Heap中,這是因為GC在heap壓縮時移動大的內存塊需要消耗大量CPU時間,通過性能調優實踐確定了85000字節這樣一個閥值
LOH只在2代GC時進行回收,采用Mark-Sweep算法,沒有壓縮處理,因此LOH中的內存分配是不連續的,使用一個空閑列表free list記錄LOH中的空閑空間,對釋放出來的空間進行管理

上圖中obj1、obj2釋放之后,其空間合并起來成為free list的一個節點,隨后被分配給obj4
什么時候觸發垃圾回收?
前面已經提到,0代和1代垃圾回收主要由閥值控制。初始時Gen 0 heap大小與CPU緩存的大小相關,運行時CLR根據內存請求狀態動態調整Gen 0 heap大小,但Gen 0和Gen 1總大小保持在16M左右
Gen 2 heap和LOH都在full GC時進行回收,full GC主要由2類事件觸發:
a). 進入Gen 2 heap和LOH的對象很多,超過了一定比例。RegisterForFullGCNotification的參數 maxGenerationThreshold、largeObjectHeapThreshold可以分別為Gen 2 heap和LOH設定這個值
b). 操作系統內存吃緊的時候。CLR會接收到操作系統內存緊張的通知消息,觸發full GC
5. Heap細節、擴容與收縮
Heap的代齡是邏輯上的結構,heap實際內存申請和分配以及釋放以segment(段)為單位,workstation GC模式segment大小為16M,server GC模式segment大小為64M。Gen 0和Gen 1 heap總是位于同一個段中,叫做ephemeral segment(新生段),因此max(Gen 0 heap size+Gen 1 heap size)≈16M || 64M,Gen 2 heap由0個或多個segments組成,LOH由1個或多個segments組成
.NET程序啟動時CLR為heap創建2個segment,一個作為ephemeral segment,另一個用于LOH。.NET使用VirtualAlloc申請和分配heap內存,在LOH中分配新對象時沒有足夠的空間,或者1代GC 時進入Gen 2的對象過多空間不夠,.NET將為LOH或者小對象heap分配新的segment。申請新的segment失敗將由EE拋出OutOfMemory異 常
Full GC后完全空閑的segments將被釋放掉,內存返回給操作系統
.NET 2.0對GC的一個重要改進是盡量改善heap碎片處理。heap碎片主要由pinned objects引起,改善措施主要有2個方面。首先是延遲升級,如果ephemeral segment存在pinned objects,則盡可能的延遲他們升級到Gen 2的時間點,考慮pinned objects的同時盡量充分利用當前ephemeral segment的空間;其次是重復利用Gen 2的空間,如果Gen 2中存在pinned objects的segments釋放出了足夠空間,該segments可能重新作為ephemeral segment使用
6. GC方式
有Workstation GC with Concurrent GC off、 Workstation GC with Concurrent GC on、Server GC 3種
Workstation GC with Concurrent GC off: 用于單CPU機器實現高吞吐量,采用一系列策略觀察內存分配以及每次GC的狀況,動態調整GC策略,盡可能使程序隨著運行時狀態的變化實現高效的GC操 作,但進行GC時會凍結所有線程
Workstation GC with Concurrent GC on: 用于響應時間非常重要的交互式程序,例如流媒體的播放等(如果一次full GC導致應用程序中斷幾秒、十幾秒時間,用戶將無法忍受)。這種方式利用多CPU對full GC進行并行處理,不是整個full GC期間凍結所有線程,而是將full GC切分成多次很短的時間對線程進行凍結,在線程凍結時間之外,應用程序仍然可以正常運行,進行內存分配,這主要通過將Gen 0 heap size設置的比non-concurrent GC大很多而實現,使得GC操作時線程仍然能夠在Gen 0 heap中進行內存分配,但如果Gen 0 heap用完后GC仍然沒有結束,線程仍然會出現阻塞。這種方式付出的代價是working set和GC所需時間比non-concurrent GC要大一些
Server GC: 用于多CPU機器的服務器應用程序實現高吞吐量和伸縮性,充分利用服務器的大內存。.NET為每個CPU創建一組heap(包括Gen 0, 1, 2和LOH)和一個GC線程,每個CPU可以獨立的為相應的heap執行GC操作,而其他CPU則正常執行處理。最佳的應用場景是多線程之間內存結構基本 相同,執行的工作相同或類似
單CPU機器上只能使用workstation GC,默認情況下為Workstation GC with Concurrent GC on方式,單CPU機器上配置為Server GC無效,仍然使用workstation GC;多CPU服務器上的ASP.NET默認使用Server GC方式,Server GC時不能使用concurrent方式
concurrent GC可以用于單CPU機器,它與CPU數量無關
對于ASP.NET程序應當盡量保證一個CPU僅對應一個GC線程,防止同一個CPU上面多個GC線程之間的沖突造成性能問題。如果使用了Web Garden則應當使用Workstation GC with Concurrent GC off。Web Garden為了提高吞吐量會導致多出幾倍的內存使用,每個work process的內存有很多重復部分,Web Garden的最佳應用場景是多個進程之間使用一個共享的resource pool,避免內存的重復并盡可能的提高吞吐量。在這一點上Server GC應當與Web Garden類似,但Web Garden在多個進程中,而Server GC是在同一個進程中通過多線程實現,目前沒有發現Server GC方面深入一些的資料,很多東西只能根據現有資料做一些猜想
為workstation GC禁用concurrent GC:
<runtime>
<gcConcurrent enabled="false"/>
runtime>
configuration>
啟用Server GC:
<runtime>
<gcServer enabled=“true"/>
>
configuration>
7. Finalization
......
參考:
Garbage Collection - Past, Present and Future, Patrick Dussud, 中文翻譯: .NET垃圾收集器的過去現在和未來(一), (二)
C# Heap(ing) Vs Stack(ing) in .NET Part I, Part II, Part III, Part IV Matthew Cochran
Garbage Collection: Automatic Memory Management in the Microsoft .NET Framework Jeffrey Richter
Garbage Collection Part 2: Automatic Memory Management in the Microsoft .NET Framework Jeffrey Richter
CLR Inside Out: Large Object Heap Uncovered Maoni Stephens
Heap: Pleasures and Pains Murali R. Krishnan
The Dangers of the Large Object Heap Andrew Hunter
Garbage Collection Notifications
Garbage Collector Basics and Performance Hints Rico Mariani
CLR Inside Out: Investigating Memory Issues Claudio Caldato and Maoni Stephens
Understanding Garbage Collection in .NET Andrew Hunter
Using GC Efficiently Part 1, Part 2, Part 3, Part 4 Maoni Stephens
Notes on the CLR Garbage Collector Vineet Gupta
The Mystery of Concurrent GC Mark Smith
Garbage Collection Curriculum Ferreira Paulo, Veiga Luís
Java theory and practice: A brief history of garbage collection Brian Goetz


 留言列表
留言列表
