概念
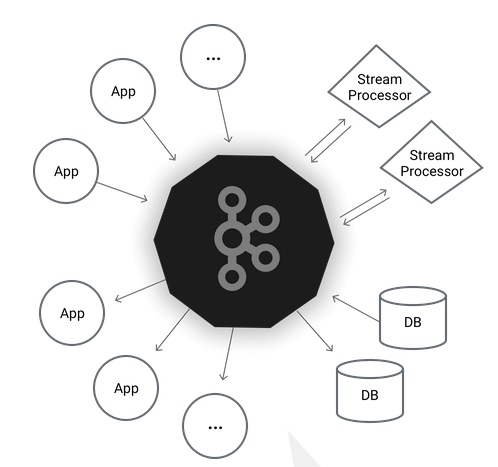
Kafka是一種高吞吐量的分布式發布訂閱消息系統,它可以處理消費者規模的網站中的所有動作流數據。 這種動作(網頁瀏覽,搜索和其他用戶的行動)是在現代網絡上的許多社會功能的一個關鍵因素。 這些數據通常是由于吞吐量的要求而通過處理日志和日志聚合來解決。 對于像Hadoop的一樣的日志數據和離線分析系統,但又要求實時處理的限制,這是一個可行的解決方案。Kafka的目的是通過Hadoop的并行加載機制來統一線上和離線的消息處理,也是為了通過集群來提供實時的消費。
- 軟件名稱
- Apache Kafka
- 開發商
- Apache軟件基金會
- 軟件平臺
- 跨平臺
- 軟件版本
- 0.8.2.2
特點
Kafka 是一種高吞吐量的分布式發布訂閱消息系統,有如下特性:
- 通過O(1)的磁盤數據結構提供消息的持久化,這種結構對于即使數以TB的消息存儲也能夠保持長時間的穩定性能。
- 高吞吐量:即使是非常普通的硬件Kafka也可以支持每秒數百萬的消息。
- 支持通過Kafka服務器和消費機集群來分區消息。
- 支持Hadoop并行數據加載。
相關知識點
Broker
Kafka集群包含一個或多個服務器,這種服務器被稱為broker[5]
Topic
每條發布到Kafka集群的消息都有一個類別,這個類別被稱為Topic。(物理上不同Topic的消息分開存儲,邏輯上一個Topic的消息雖然保存于一個或多個broker上但用戶只需指定消息的Topic即可生產或消費數據而不必關心數據存于何處)
Partition
Partition是物理上的概念,每個Topic包含一個或多個Partition.
Producer
負責發布消息到Kafka broker
Consumer
消息消費者,向Kafka broker讀取消息的客戶端。
Consumer Group
每個Consumer屬于一個特定的Consumer Group(可為每個Consumer指定group name,若不指定group name則屬于默認的group)。
安裝與部署
前提
kafka需要有zookeeper分布式調度組件的支持,所以我們需要先安裝它,具體方法請查詢大叔這篇文章《ZookeeperLinux環境下的部署》
下載
curl -L -O http://mirrors.cnnic.cn/apache/kafka/0.9.0.0/kafka_2.10-0.9.0.0.tgz
解壓
tar zxvf kafka_2.10-0.9.0.0.tgz
查看目錄結構
- /bin 操作kafka的可執行腳本,還包含windows下腳本
- /config 配置文件所在目錄
- /libs 依賴庫目錄
- /logs 日志數據目錄,目錄kafka把server端日志分為5種類型,分為:server,request,state,log-cleaner,controller
啟動Kafka
bin/kafka-server-start.sh config/server.properties & //&表示進程將在后端執行
查看服務是否啟動成功
netstat -tunlpegrep "(21819092)"
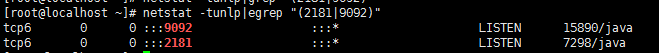
這樣說明我們的9092就是kafka的數據通訊端口已經啟動了,2181是我們的zookeeper通訊端口,說明它們處于正常的監聽狀態!
希望通過這篇文章,讓大家對kafka,zookeepr,centos有一個學習與了解!
感謝各位的閱讀!
文章列表
